With Wooly AI, the world’s first hardware-agnostic hypervisor for ML GPU clusters.
The Wooly AI Difference
Cross-vendor CUDA Execution
With Wooly Hypervisor Just-In-Time (JIT) compilation, we enable the execution of unmodified PyTorch and other CUDA applications in heterogeneous GPU vendor environments that are on-premises, in the cloud, or both.
PyTorch/vLLM Application
Wooly GPU Hypervisor
Just-In-Time Compilation
Nvidia Hardware
AMD Hardware
Maximum Utilization & Concurrency
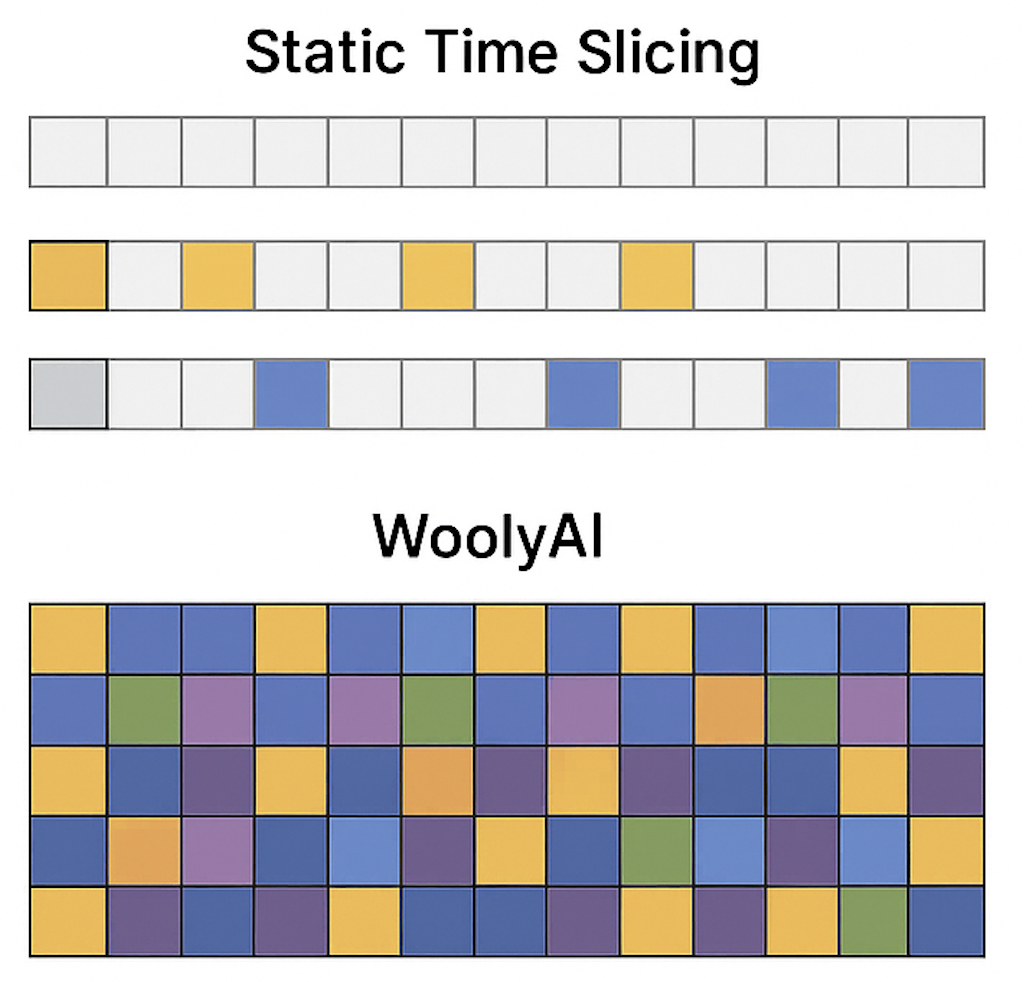
Unlike traditional GPU infrastructure management approaches, which rely on static time-slicing or static partitioning, WoolyAI JIT compiler and runtime stack can measure and dynamically reallocate GPU compute cores across concurrent ML workload processes based on real-time usage, workload priority, and VRAM availability. This results in 100% utilization of GPU compute cores consistently.
Key Benefits of Wooly AI
GPU independence
On both Nvidia and AMD
Higher ML Ops team productivity
No code rewrites and less time spent right-sizing & optimizing GPU clusters
Faster deployment of ML apps
Concurrent isolated execution of models to test, roll out, and iterate on AI features without infrastructure bottlenecks
Maximized infrastructure utilization
Dynamic GPU cores and memory sharing at runtime across different ML applications based on demand and priority
Peace of mind
Multi-model orchestration across clusters with native performance and reliability
Greater operational flexibility
Live migration of ML apps across GPU clusters. Works with on-prem GPUs, cloud GPU instances, and hybrid environments.
Wooly AI Use Cases
Consolidate multiple ML teams on shared infrastructure for both Nvidia and/or AMD GPUs
Serve many ML teams (training, inference, fine-tuning, RL, vision, recommender systems) on single or multi GPU node cluster without hard partitioning and with job isolation, predictable SLA, unified pipeline for both Nvidia and AMD.
Improve GPU and VRAM utilization of Nvidia and/or AMD GPU cluster
Eliminate the “one-job-per-GPU” bottleneck with concurrent execution of fine-tuning, inference, training, or simulation jobs on single GPU, dynamic allocation and management of GPU compute cores and VRAM, Live-migrate or backfill jobs to underutilized GPUs, go from 40-50% GPU utilization to 100% utilization.
Cost effectively scale-out Nvidia GPU infrastructure with AMD GPU
Expand Nvidia only cluster with cost efficient AMD GPUs without any changes to existing CUDA ML workloads. Single unified Pytorch containers for both Nvidia and AMD with hardware aware optimization, centralized dynamic scheduling across mixed GPU clusters.
Migrate from Nvidia to AMD GPUs without rewriting any code
Run the same Pytorch CUDA code without any changes on AMD GPUs, Unified container to run Pytorch and inference on both Nvidia and AMD, Native performance on both CUDA and AMD with runtime leveraging hardware-aware optimizations for both hardware.
Set up CI/CD and Model A/B Testing Pipelines on shared infrastructure
Run many concurrent CI/CD pipelines on single GPUs in an isolated compute/memory sandbox, scheduler dynamically adjusts GPU cores and memory allocation to meet SLA and job priority, run pipelines on both Nvidia and AMD without duplication.
About Us
Wooly AI was created by a world-class virtualization team with decades of experience developing and selling virtualization solutions to enterprise customers.