WoolyAI decouples your workloads from physical GPU hardware.
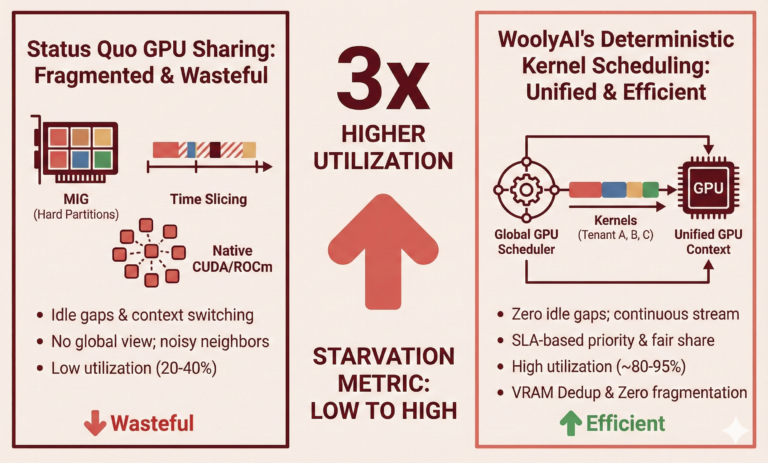
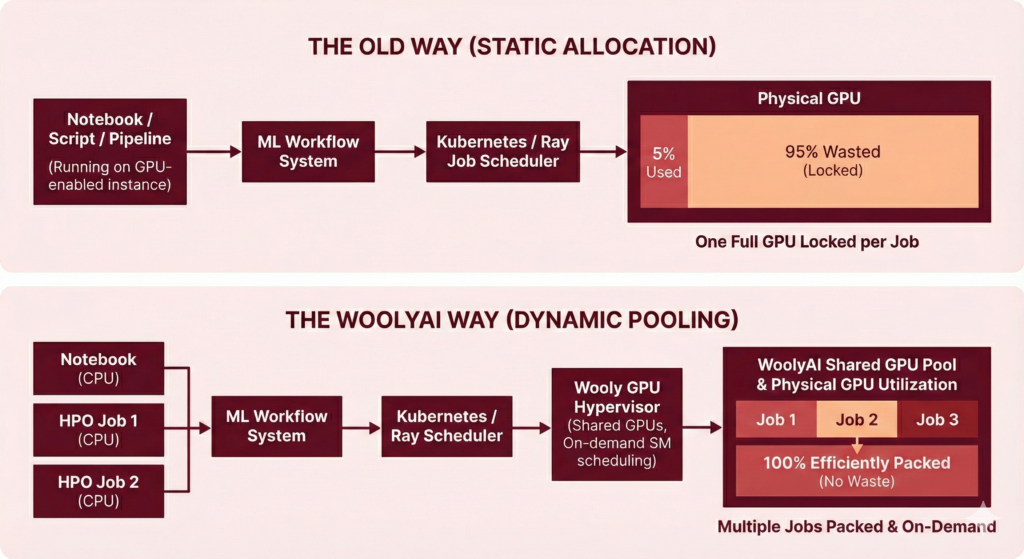
 The Old Way (Static Allocation)
The Old Way (Static Allocation)
- Flow: Pipeline Step -> Requests GPU -> Locks 1 or more Full Physical GPU.
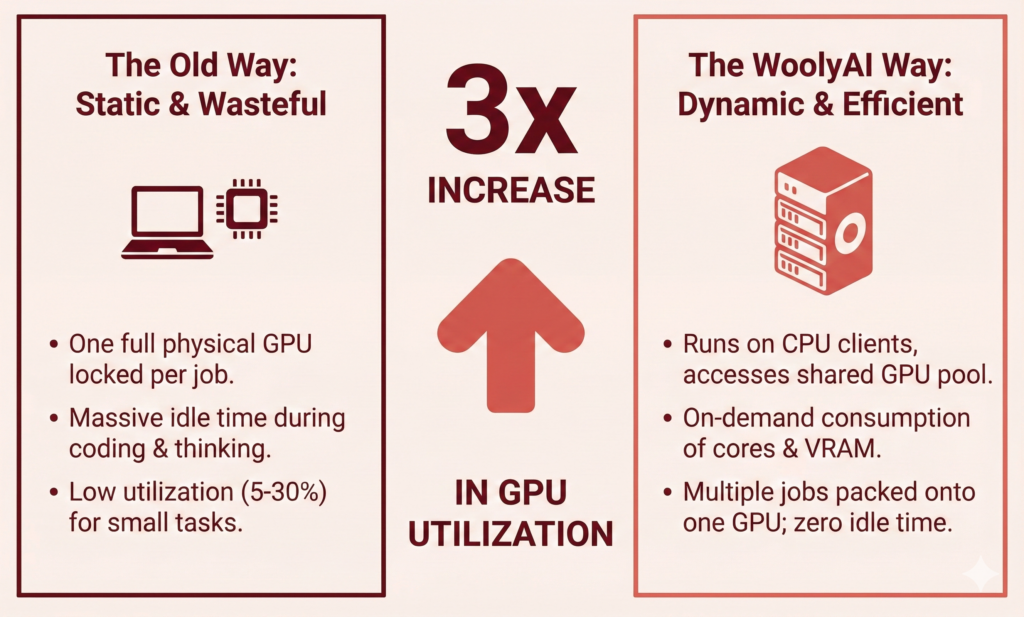
- Result: A Jupyter notebook using 5% compute power blocks 100% of a GPU.
 The WoolyAI Way (Shared GPU Pool and Runtime GPU cores and VRAM scheduling
The WoolyAI Way (Shared GPU Pool and Runtime GPU cores and VRAM scheduling
- Flow: Pipeline Step running on CPU-only host-> Submits Job -> Code requiring GPU executes on GPU from a shared GPU pool along with other jobs.
- Result: Jobs run on CPU-only infrastructure (like laptops or standard CPU instances) while kernel compute is offloaded to the shared GPU pool enabled by WoolyAI.
- Efficiency: GPU Resources are consumed on demand. Multiple jobs are “packed” onto the same physical GPU based on priority and actual utilization.
Here is how WoolyAI transforms your daily dev/test operations.
1. For Prototyping & Notebooks
|
|
| Locked Resources: You spin up a server with 1 GPU. It sits idle while you code. | Virtual Resources: Your notebook runs on a cheap CPU instance. Code requiring GPU Compute is sent to the shared GPU pool. |
| Low Utilization: You use 5–30% capacity. | High Density: Support 3x more active users on the same hardware. |
2. For Small-Scale Experiments (HPO)
|
|
| Queue Jams: Dozens of HPO jobs fill the cluster immediately. | Smart Packing: The scheduler packs multiple variants (e.g., 4 runs) onto a single GPU. |
| Inefficient: Small batch sizes and short runs waste the overhead of a full GPU. | Fairness: Short and long jobs co-exist without starvation. |
3. For Canary Training
|
|
| Over-Provisioning: You dedicate entire GPUs to ensure performance. | Flexible SLAs: Choose “Exclusive Mode” for raw power or “High-Priority Shared Mode” to guarantee performance while filling gaps with lower-priority tasks. |