A New Approach to GPU Sharing: Deterministic, SLA-Based GPU Kernel Scheduling for Higher Utilization
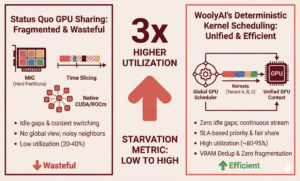
A New Approach to GPU Sharing: Deterministic, SLA-Based GPU Kernel Scheduling for Higher Utilization Modern GPU-sharing techniques like MIG and time-slicing improve utilization, but they fundamentally operate by partitioning or alternating access to the device—leaving large amounts of GPU compute
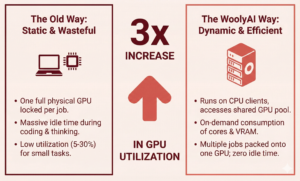
Triple Your GPU Utilization in ML Development with WoolyAI
Stop letting idle GPUs drain your budget during the experimentation phase. Machine learning development is expensive, but it doesn’t have to be wasteful. In the typical ML lifecycle, the “experimentation, dev, and test” stages are notorious for low GPU utilization.